Hallo AI darmowa zamiana obrazu w wideo dzięki sztucznej inteligencji. Jak sprawić aby wasze zdjęcia lub grafiki ożyły? Teraz to proste sprawdźcie, jak to działa. Dzięki Hallo AI darmowemu, otwarto-źródłowemu narzędziu AI, możesz sprawić, że dowolne zdjęcie lub grafika ożyje tzn. postać zacznie mówić, a nawet śpiewać jeśli chcesz. Wyobraź sobie, że wystarczy tylko jedno ujęcie i nagranie dźwiękowe, a to magiczne narzędzie automatycznie zsynchronizuje ruchy ust i mimikę, tworząc niesamowity efekt.
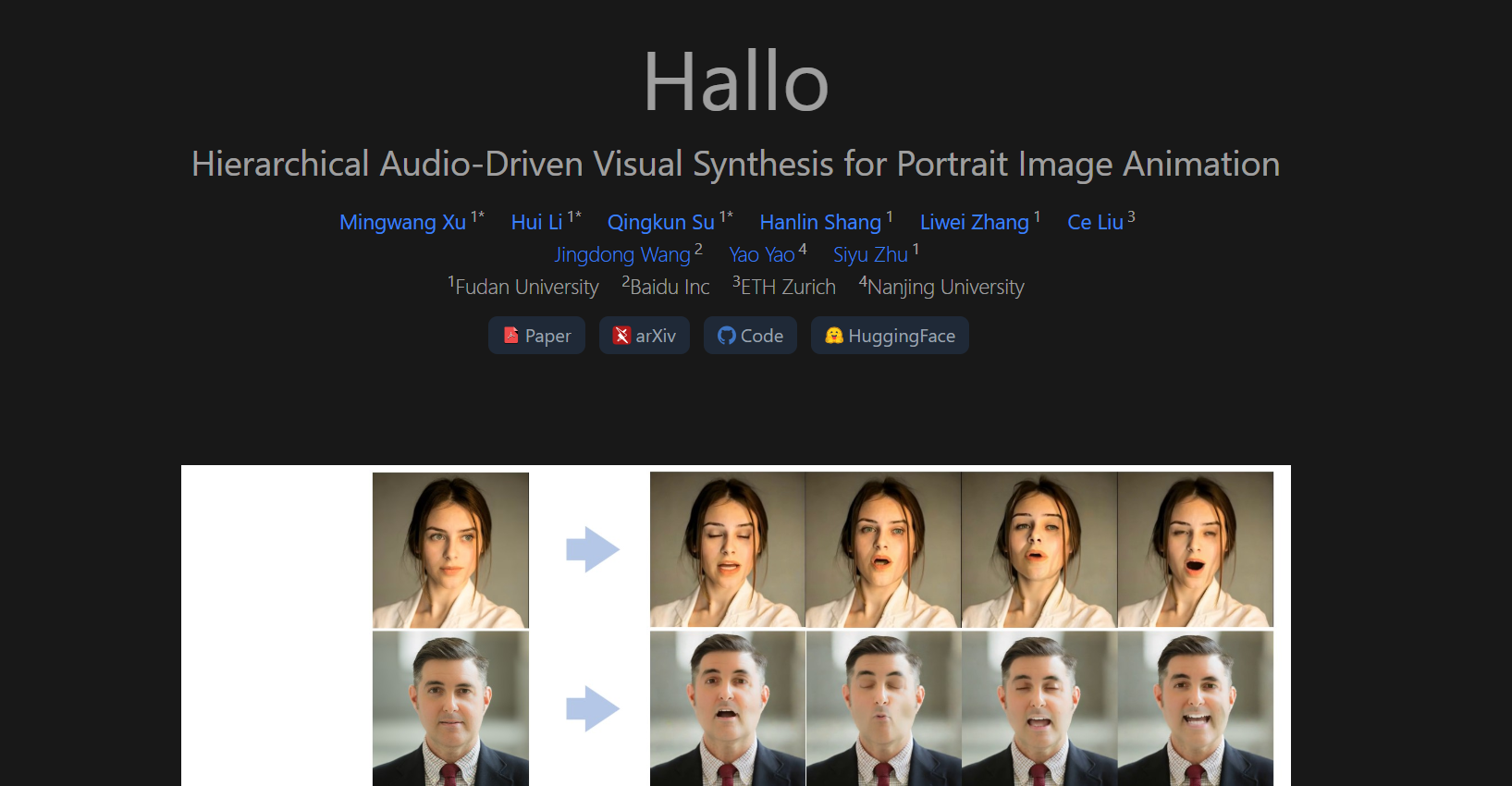
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation
Hallo to nowatorska metoda animacji portretów, napędzana dźwiękiem (audio-driven), opracowana przez zespół badaczy i opublikowana w czerwcu 2024 roku na arXiv (autorzy: Mingwang Xu i inni). Projekt skupia się na generowaniu wysokiej jakości, dynamicznych animacji twarzy na podstawie pojedynczego obrazu portretowego i sekwencji audio, takich jak mowa. Wyróżnia się hierarchicznym podejściem do syntezy wizualnej sterowanej dźwiękiem, co pozwala na precyzyjne zsynchronizowanie ruchów ust, ekspresji i pozycji głowy z wejściem audio.
Kluczowe cechy:
- End-to-End Diffusion Model:
- Hallo odchodzi od tradycyjnych metod opartych na pośrednich modelach parametrycznych (np. 3D Morphable Models) na rzecz podejścia opartego na modelach dyfuzyjnych (diffusion models).
- Wykorzystuje Stable Diffusion 1.5 jako podstawę, integrując UNet do usuwania szumu, ReferenceNet do zachowania spójności tekstur i mechanizmy temporalne dla płynności animacji.
- Hierarchical Audio-Driven Visual Synthesis (HADVS):
- Kluczowy moduł, który dzieli proces syntezy na poziomy hierarchiczne, zapewniając dokładne mapowanie między dźwiękiem a ruchami wizualnymi (usta, ekspresje, pozy).
- Używa mechanizmu cross-attention (uwagi krzyżowej) między audio a wizją oraz adaptacyjnych wag, by precyzyjnie kontrolować detale animacji.
- Wysoka jakość i personalizacja:
- Generuje animacje w rozdzielczościach do 512×512 (z potencjałem skalowania), oferując fotorealistyczne rezultaty.
- Umożliwia dostosowanie ekspresji i ruchów do indywidualnych cech tożsamości poprzez fine-tuning na danych referencyjnych.
- Dane techniczne:
- Wymaga ok. 9,77 GB pamięci GPU i generuje animację w 1,63 sekundy (dla krótkich klipów).
- Testowane na zbiorach danych HDTF, CelebV i niestandardowym zestawie „wild”.
- Zastosowania:
- Tworzenie realistycznych awatarów do gier, VR czy filmów.
- Personalizowane animacje do komunikacji wirtualnej.
- Badania nad syntezą audio-wizualną.
Jak działa?
- Wejście: Użytkownik dostarcza pojedynczy obraz portretowy i plik audio (np. nagranie mowy).
- Proces:
- Audio jest analizowane pod kątem cech, takich jak fonemy, rytm i intonacja.
- HADVS hierarchicznie mapuje te cechy na ruchy twarzy (usta → ekspresje → pozy głowy).
- Model dyfuzyjny generuje klatki wideo, korzystając z ReferenceNet, by zachować spójność z oryginalnym obrazem.
- Wyjście: Płynna animacja zsynchronizowana z dźwiękiem.
Przykład:
- Prompt: Obraz osoby + audio: „Witaj, jak się masz?”
- Efekt: Wideo, w którym twarz porusza ustami, zmienia ekspresję i lekko kiwa głową w rytm słów.
Plusy:
- Lepsza synchronizacja ust i naturalność ruchów w porównaniu do tradycyjnych metod (np. SadTalker, AniPortrait).
- Wysoka jakość wizualna – potwierdzona metrykami FID (Fréchet Inception Distance) i FVD (Fréchet Video Distance).
- Elastyczność w kontroli różnorodności ruchów i ekspresji.
Minusy:
- Ograniczenia sprzętowe – wymaga mocnego GPU.
- Potencjalne problemy z synchronizacją przy szybkich lub złożonych ruchach.
- Etyczne kwestie związane z prywatnością i zgodą na wykorzystanie wizerunków (mitigowane przez transparentność polityki danych w badaniach).
Dostępność:
- Open-source: Kod i wagi modelu są dostępne na GitHubie (https://fudan-generative-vision.github.io/hallo).
- Testowanie: Obecnie głównie w środowisku badawczym – brak komercyjnej wersji online jak Kling czy Sora, ale można uruchomić lokalnie po pobraniu.
Porównanie z innymi:
- Sora (OpenAI): Sora generuje dłuższe filmy (do 20 sekund) i ma bardziej komercyjny charakter, ale nie skupia się na animacji portretów.
- Kling AI: Kling oferuje dłuższe klipy (do 2 minut) i szersze style, ale Hallo przewyższa go w precyzji synchronizacji audio-wizualnej.
- AniPortrait: Używa pośrednich reprezentacji 3D, co może ograniczać naturalność; Hallo działa end-to-end, co daje lepsze rezultaty w jakości.
Hallo AI to krok naprzód w syntezie audio-wizualnej, szczególnie dla animacji portretów. Wypróbuj online na stronie https://www.segmind.com/models/hallo